Czas na kolejny wpis 🙂
W poprzednim wpisie opisywałem komenę commit (tutaj). W tym wpisie chciałbym się skupić na kolejnych 3 bardzo ważnych komendach w GIT, a mianowicie: git push, git pull oraz git fetch.
Zacznę od wyjaśnienia każdej z komend.
Git push – służy do wysyłania zakomitowanych (zatwierdzonych) wersji do repozytorium zdalnego.
Git pull – służy do ściągnięcia nowszych commitów ze zdalnego repozytorium do nas lokalnie.
Git fetch – odświeża informację o historii commitów z repozytorium zdalnego. Dzięki tej komendzie będziemy w stanie ściągnąć informację, czy najnowszy commit, który mamy lokalnie jest faktycznie najnowszy, czy na repozytorium zdalnym pojawiło się coś nowego.
Mowa o wrzucaniu i ściąganiu kodu do repozytorium znajdującym się na serwerze, ale jakim serwerze? Serwerze, na którym można składować repozytorium gita w wersji minimalnej. Może być to inny komputer lub inny dysk podpięty do komputera, lub inny katalog na tym samym dysku. W wersji bardziej profesjonalnej może być to np. dedykowany serwer, gdzie są przechowywane repozytoria lub usługa taka jak GitHub.
Poniżej przedstawię jak utworzyć na GitHub nowe repozytorium, podpiąć się do niego i wysłać tam nasze lokalne commity.
Do roboty 🙂
Akt 1. Tworzenie nowego repozytorium na GitHub.
Zacznijmy od zalogowania się do konta na GitHub, następnie w prawym górnym menu wybierzmy opcję “Your Repositories”.
Następnie wybieramy opcję “New”.
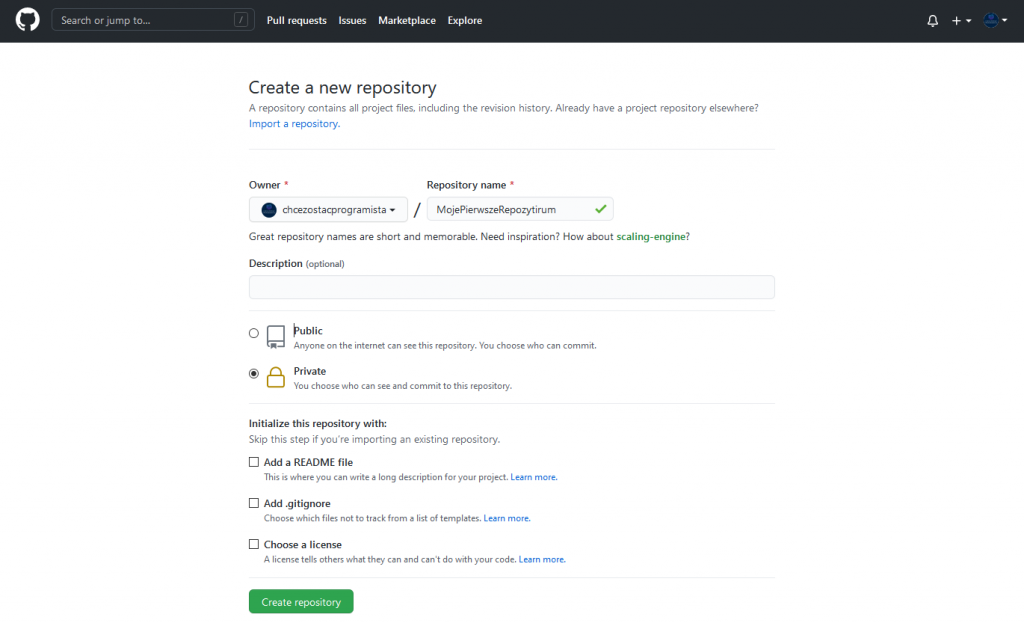
Musimy podać nazwę naszego repozytorium, zdecydować, czy nasze repozytorium ma być publiczne dla wszystkich, czy prywatne i dostęp do niego będą miały tylko osoby, którym nadamy odpowiednie uprawnienia. Dodatkowo możemy dodać do nowo tworzonego repozytorium np. plik “readme”, w którym zwykle przechowuje się jakieś podstawowe informacje o zawartości repozytorium lub plik “gitignore”, w którym można zdefiniować rozszerzenia plików, które chcemy, aby nie były śledzone w naszym repozytorium (o pliku gitignore będzie w kolejnych wpisach).
Dodatkowo świetną sprawą jest możliwość zdefiniowania jakiego rodzaju licencja obowiązuje na projekt, który tworzymy. Dzięki temu osoby, które będą chciały skorzystać z naszego projektu, czy kodu w nim zawartym, będą wiedziały, czy mogą go użyć np. do projektów komercyjnych.
Mamy już nasze repozytorium 🙂 Możemy je klonować. W tym celu możemy skorzystać z linku, który został wygenerowany.
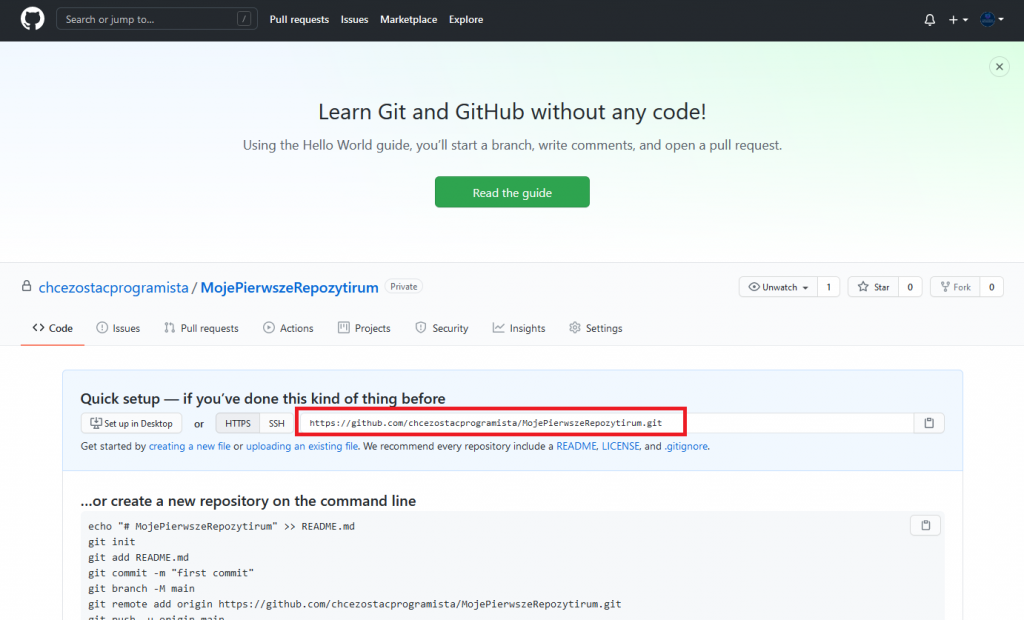
Akt 2. Klonowanie naszego repozytorium.
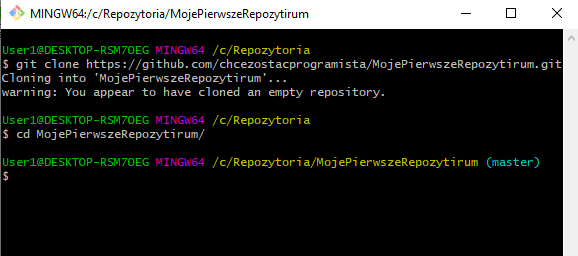
W tym celu wykonajmy komendę git clone w konsoli. Następnie przechodzimy do katalogu naszego repozytorium.
Akt 3. Tworzenie commitu.
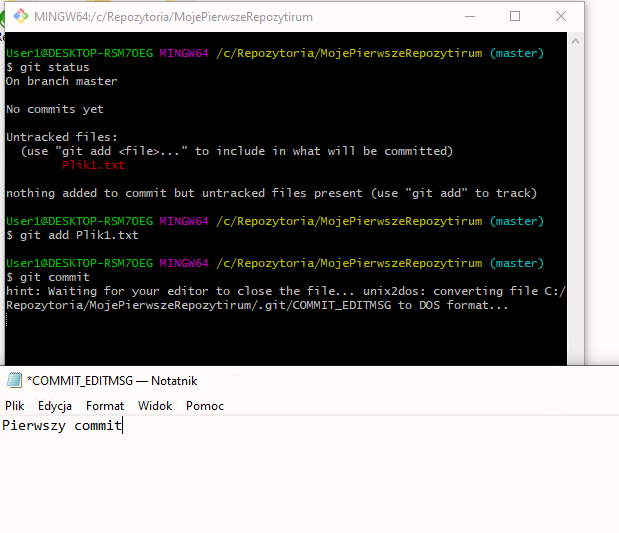
Stwórzmy plik w naszym repozytorium, w którym wpiszemy tekst “hello world”, a następnie zróbmy commit.
Akt 4. Git push.
Wywołujemy komendę git push i oto nasz commit ląduje na GitHub.
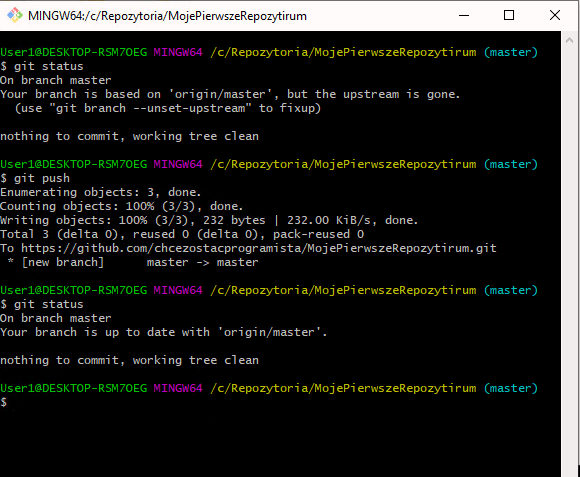
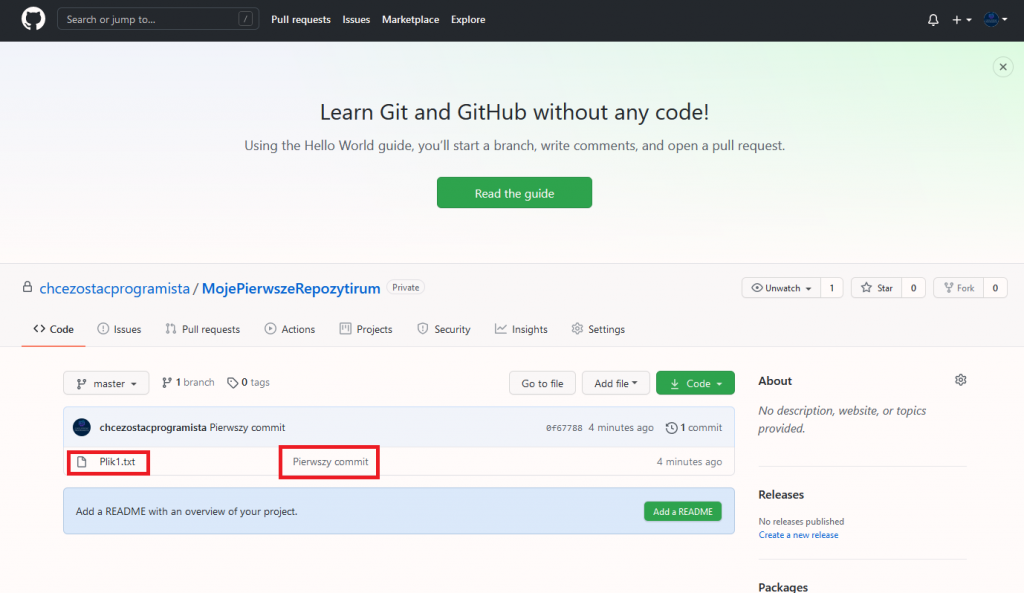
Mamy nasze zmiany na serwerze !!! Sprawdźmy jak to wygląda na GitHub.
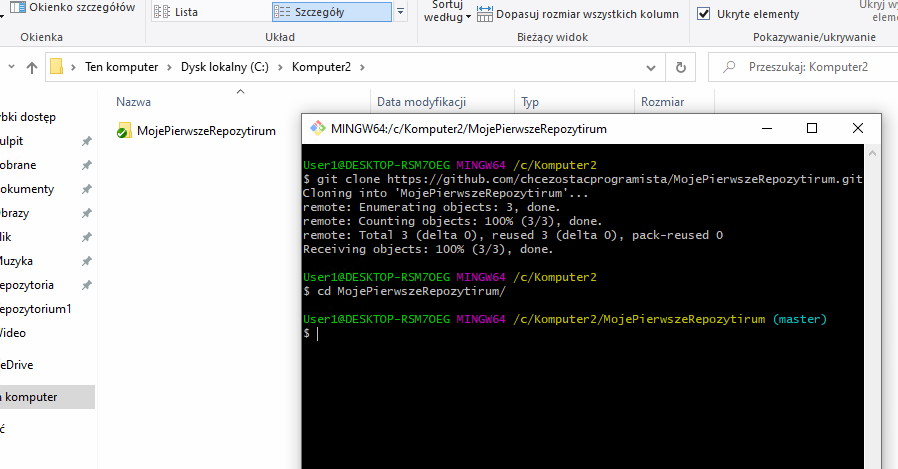
Zróbmy sobie nowy katalog, w którym ściągniemy nasze repozytorium ponownie, stworzymy drugi commit, a następnie wrócimy do pierwszego katalogu, aby zaprezentować pozostałe 2 komendy. Zasymulujemy tutaj sytuację, gdy do repozytorium dodaje coś więcej niż jedna osoba lub robimy to np. z różnych komputerów.
Tworzymy nowy katalog o nazwie “Komputer2” i tam klonujemy nasze repozytorium.
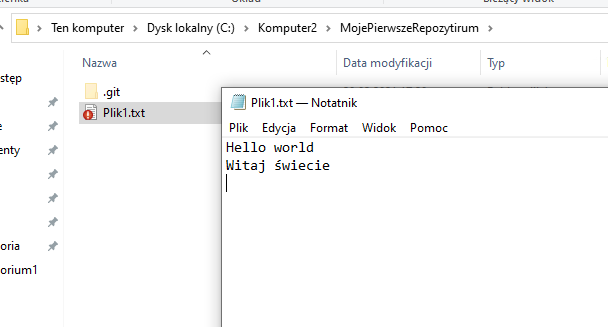
Dodajmy kolejną linijkę do pliku tekstowego o treści “Witaj świecie”.
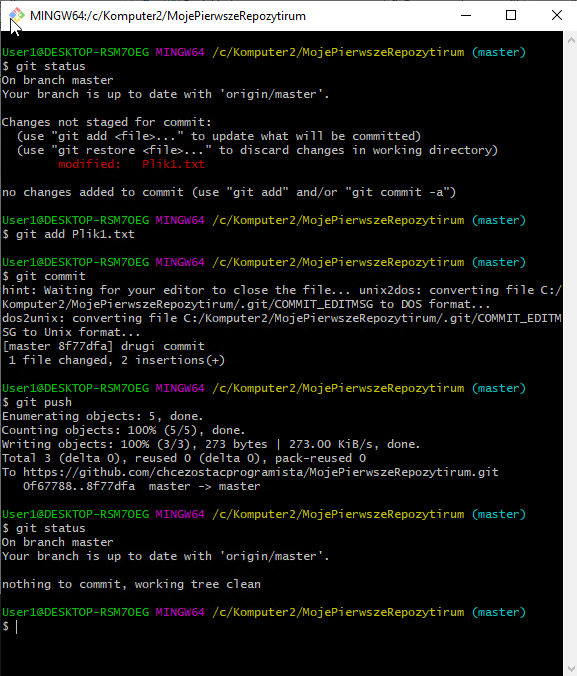
Powtórzmy operację, stwórzmy commit i zróbmy push na serwer.
Sprawdźmy nasz GitHub.
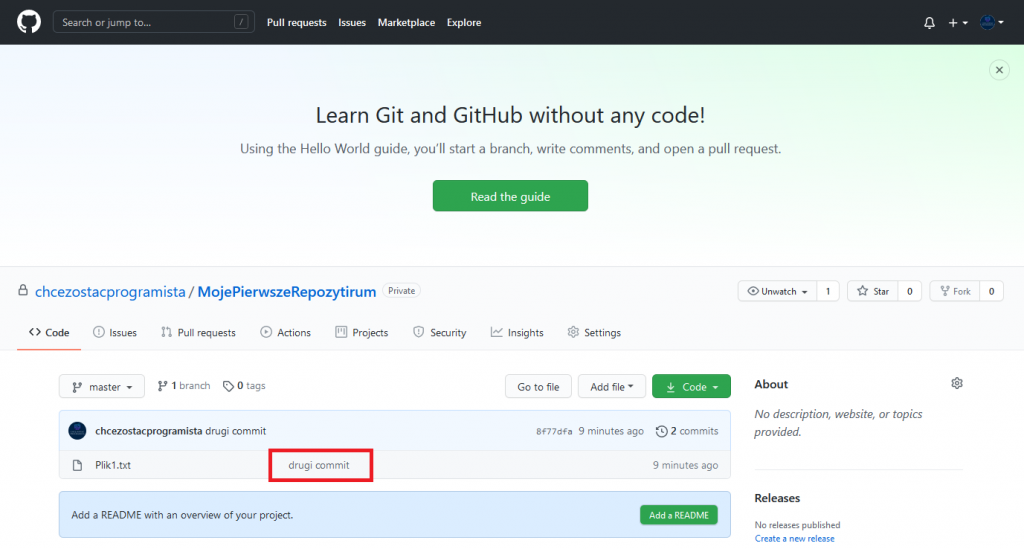
Faktycznie na stronie pojawił się nasz “drugi commit”.
Akt 5. Pobieranie zmian ze zdalnego repozytorium.
Wróćmy do naszego katalogu C:/Repozytoria/MojePierwszeRepozytorium i wywołajmy komendę git status. Można zobaczyć, że git twierdzi, że jesteśmy aktualni z serwerem “Your branch is up to date with ‘origin/master'”. (jest to nieprawda, bo przecież na serwerze znajduje się “drugi commit”, ale wrócimy do tego później).
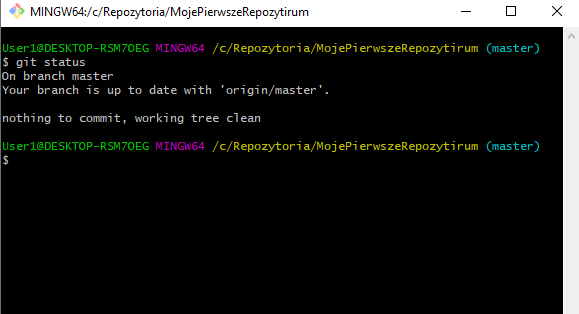
Wykonajmy w takim razie komendę git pull, która ma za zadanie ściągnąć najnowsze wersje ze zdalnego repozytorium.
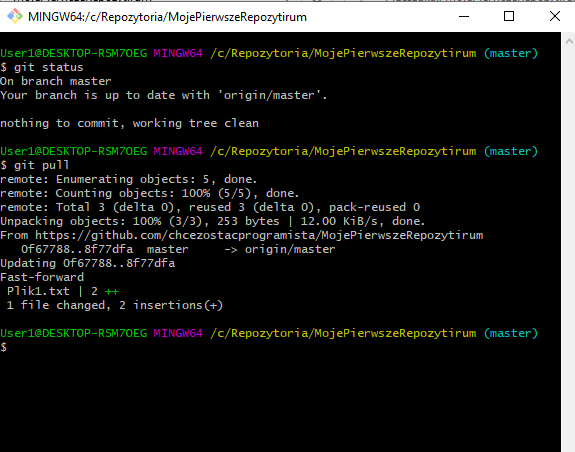
Jak widać zostały zaciągnięte zmiany. Możemy sprawdzić jaki faktycznie commit jest ostatni wywołując komendę “git log”.
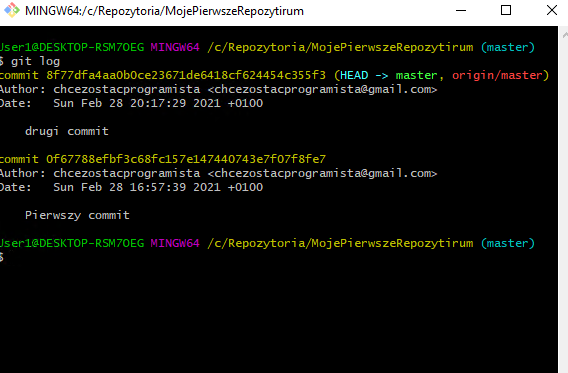
Udało się wysłać i pobrać zatwierdzone (commit-owane) wersje ze zdalnego repozytorium za pomocą “git push” i “git pull”.
To nie wszystko. Wspominałem jeszcze o trzeciej komendzie git fetch, ale nie pokazałem jak ona działa.
Cofnijmy się do momentu kiedy robiliśmy git status i nasz git twierdził, że jesteśmy aktualni “Your branch is up to date with ‘origin/master'”, co było nieprawdą. Komenda git fetch odświeża informację pomiędzy repozytorium zdalnym, a lokalnym, ale nie ściąga commitów lokalnie.
Wykonajmy w takim razie git fetch, gdy na serwerze znajduje się nowszy commit i nasza lokalna wersja nie jest najaktualniejsza.
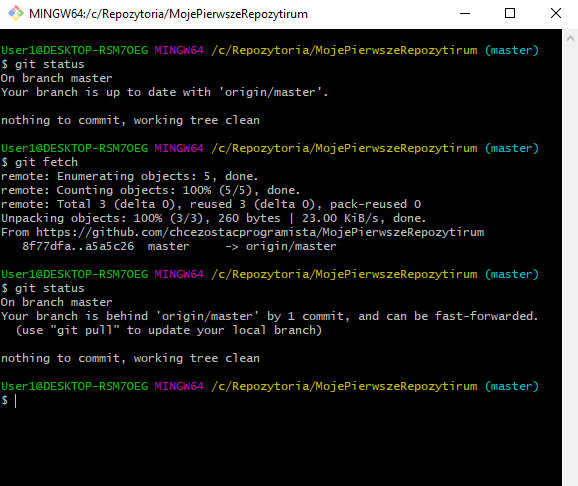
Jak widać na powyższym zrzucie ekranu wykonuję komendę git status. Git twierdzi, że wszystko jest aktualne. Następnie wykonuję git fetch i ponownie git status, wtedy Git zaczyna jednak mówić, że jestem jeden commit do tyłu w stosunku do zdalnego repozytorium.
Dlaczego się tak dzieje, że za pierwszym wywołaniem git status Git twierdził, że wszystko jest aktualne??
To bardzo proste, ponieważ nie ma w Git czegoś takiego, jak sprawdzanie na bieżąco, czy coś się nie zmieniło na serwerze. Dopiero wywołanie odpowiedniej komendy powoduje wymianę informacji (odświeżenie) pomiędzy lokalnym, a zdalnym repozytorium.
Ok, to tyle 🙂 Mam nadzieję, że zaprzyjaźnisz się z git pull i git push i będziesz używał tych komend (zarówno w konsoli, jak i w programach graficznych) codziennie, a Git stanie się nieodzowną częścią Twojej pracy każdego dnia.